近年來,對話式人工智慧(Conversational AI)已被廣泛的應用於客戶服務、娛樂和健康照護等各式生活場景中,例如手機語音助理、智慧音箱、陪伴機器人等。國立陽明交通大學電機學院終身講座教授簡仁宗提到,對話式AI包含語音及語言,兩者之間該如何互通共榮將是未來的關鍵議題。他的團隊也試著打造一個照護聊天機器人,展示了目前對話式AI已經能實現順利對答並正向鼓勵對談者。

隨著技術的進展,人們也開始期待未來能以語音更順暢地與機器進行對談,但為了能讓機器即時理解對話內容並回應,當中還有許多任務需要處理,包括語音辨識、語音合成、語言理解、語言生成,以及對話管理都是重要議題。簡仁宗指出,這些領域分別已有許多研究者投入,而當前最大的挑戰就是將這些系統整合,並實際解決真實問題。
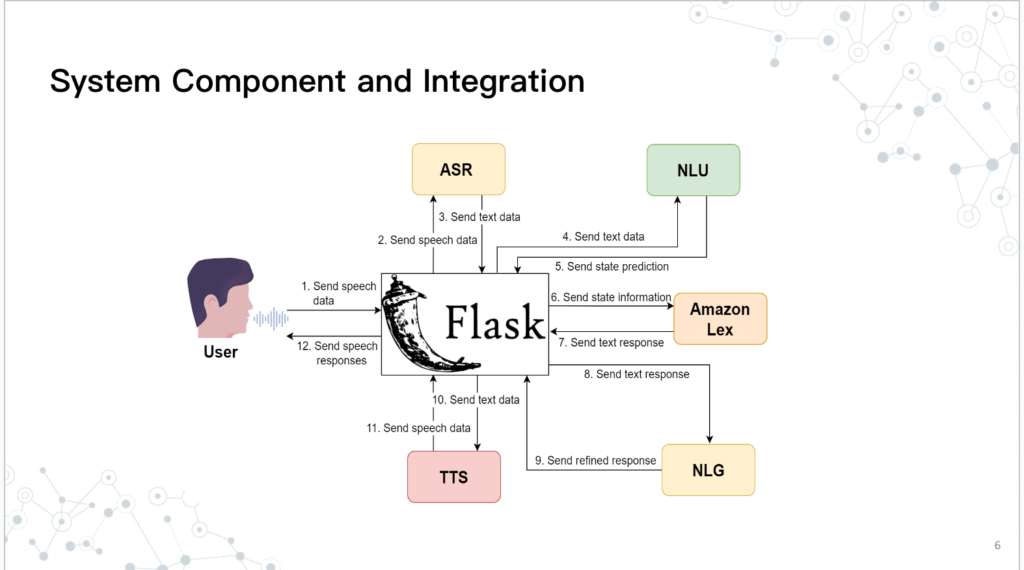
簡仁宗解釋,語音系統中必須處理整個資料串接的過程,可以看到下圖的架構中,當使用者的聲音輸入之後,會透過不同的路徑進行處理與語音生成,例如利用ASR將語音轉成字串後,進行理解,接著針對理解的狀態進行預測,再透過對話機制產生回應及語言生成與合成。由於這些路徑都是雙向的過程,也會需要投入相當多的心力建立平台,並整合這些複雜的工作。
目前看到的基礎模型並非一蹴可幾,而是經過幾十年的累積而成。從早期的隱藏式馬可夫模型,漸漸到深度學習之後,開始出現End to End的模型;及至目前基於基礎模型的基礎將之適用於具體的領域上,並透過技術提升表現效益。簡仁宗說,最關鍵的技術就是「attention」。他提到,基礎模型的基礎就是Transformer,可以將問題產生成複雜的變化,輸入與輸出都是序列,而訊息會經過位置的編碼,並經過N層的「attention」。
後來出現的BERT (Bidirectional Encoder Representations from Transformers,來自轉換器的雙向編碼器表示) 也是基於Transformer延伸出的模型,是龐大且需要密集運算的模型,至少使用了1.1億個參數,透過自監督式的學習,可以在無標籤資料集上訓練,且僅需要小幅修改,即可推廣至各種應用上。隨後接續出現的GPT2及GPT3,不僅資料量與參數量越來越大,能解決的工作複雜度與任務也越來越多。同時,花費的訓練金額也越來越多。
他提到,不同的component都有不同的基礎模型,在語音辨識上目前較為熱門的基礎模型為Wav2Vec,不僅可以取得程式碼,效能也極為優異。在語音合成部分,也有許多不同的模型與平台,例如Tacotron2,當中極為重要的部分為WaveNet vocoder,可以將語音訊號生成出來,且達到接近人聲的一流品質。另一個重要的模型則是Fastspeech2,優點是速度快且合成的品質很好。在這個基礎之下,我們必須要做Pre-Trained,並且延伸至不同的應用,以及提升各個任務的表現效益。而目前GPT系列的模型在語音生成及理解上都有蠻優異的表現,甚至在對話管理上可能也不太需要,但這仍是一個值得討論的議題。
如何利用既有的Pre-Trained Models,並套用至想解決的問題上,當中有個重要的過程為「fine-tune(微調)」,不過由於基礎模型的參數量太大,即使是微調的工程也十分龐大並提升參數的表現。
簡仁宗的團隊也利用公開的資源與素材,並進行技術整合以及對話流程的設計,開發了一個照護聊天機器人系統,不僅已能順利與人對話,並提供對應的內容,也展現了目前text to speech (TTS)的基礎模型已能有不錯的成果。
更多對話系統打造的技術與挑戰分享,請點選連結觀賞影片
全文轉載自鴻海研究院TECH BLOG
鴻海計畫往電動車、數位健康與機器人發展,而這三個領域的技術突破,則是要靠著人工智慧、通訊技術與半導體研發做突破。這就是鴻海著名的 3+3 政策。在這些領域上想要加速,資訊安全與未來新世代算力也會是突破與發展的重點。因此,鴻海研究院 5 大研究所與1個實驗室就包含人工智慧研究所、半導體研究所、新世代通訊研究所、資通安全研究所、量子計算研究所、離子阱實驗室。
- HHRI/鴻海啟用全台業界首座離子阱實驗室 締造量子科技里程碑 - 2023 年 10 月 28 日
- HHRI/AI技術的發展如何影響半導體的發展?專訪鴻海研究院半導體所郭浩中所長 - 2023 年 9 月 23 日
- HHRI/攜手產學界開創新模式 鴻海研究院突破碳化矽半導體技術 - 2023 年 9 月 16 日